
Gli scienziati di Microsoft hanno brevettato un metodo per comprimere la profondità delle Reti Neurali (che stanno alla base delle più avanzate IA), in modo da demandare quanto più possibile l’elaborazione tutta lato server, e velocizzare il response time di tutti i nostri dispositivi.
Una rete neurale molto vasta e capace di riconoscere ciò che gli viene chiesto, richiede circa 30 milioni di parametri, e avere un buon riconoscimento vocale richiede una elaborazione RAM e potenza di calcolo che difficilmente potrebbe avere anche lo smartphone più avanzato del momento.
Il metodo brevettato, può ridurre di 20 volte la grandezza delle reti neurali, in modo tale da poter avere un buon riconoscimento vocale su più dispositivi, siano essi computer, tablet o smartphone.
Ecco qualche dettaglio che può far capire di cosa stiamo parlando:
Le tecnologie descritte nel presente documento si riferiscono alla conversione di un sistema di rete neurale con un’orma relativamente grande (ad esempio, maggiore spazio in memoria) in un sistema di rete neurale con un’orma relativamente più piccola (ad es., più piccola dimensione di archiviazione), tale che il sistema di rete neurale con l’orma più piccola può essere più facilmente utilizzato su uno o più dispositivi con risorse limitate. Gli aspetti sopracitati si riferiscono a ridurre le dimensioni di archiviazione di una grande orma DNN (Deep Neural Network) avendo una o più matrici. Una o più matrici della grande orma DNN, memorizzano valori numerici che vengono utilizzati nel valutare le caratteristiche di un segnale audio. La valutazione di queste funzionalità con i valori numerici nelle matrici permettono alla grande orma DNN, di determinare una probabilità che il segnale audio corrisponde ad una particolare espressione, parola, frase o frase.Gli aspetti del presene brevetto si riferiscono alle tecniche di conversione, che quando applicate a uno o più matrici di una grande orma DNN, risultano in una matrice di dimensioni più piccole. Una tecnica di conversione include l’analisi dei vettori di una matrice DNN di una grande orma per identificare porzioni dei vettori (ad es., sub-vettori) che hanno simili proprietà numeriche. I sub-vettori con simili proprietà numeriche vengono raggruppati. Un’approssimazione (o codeword) del gruppo può essere determinata per un gruppo. Parole in codice quindi sono indicizzate in un cifrario, che contiene l’indirizzo delle parole in codice. In aspetti della tecnologia, dopo aver ottenuto il cifrario, le parole in codice possono essere ottimizzate utilizzando una varietà di tecniche di addestramento della rete neurale. Utilizzo del codebook per indice di parola di codice appropriato, corrisponde ai gruppi di sub-vettori, formando una matrice DNN di piccola orma.
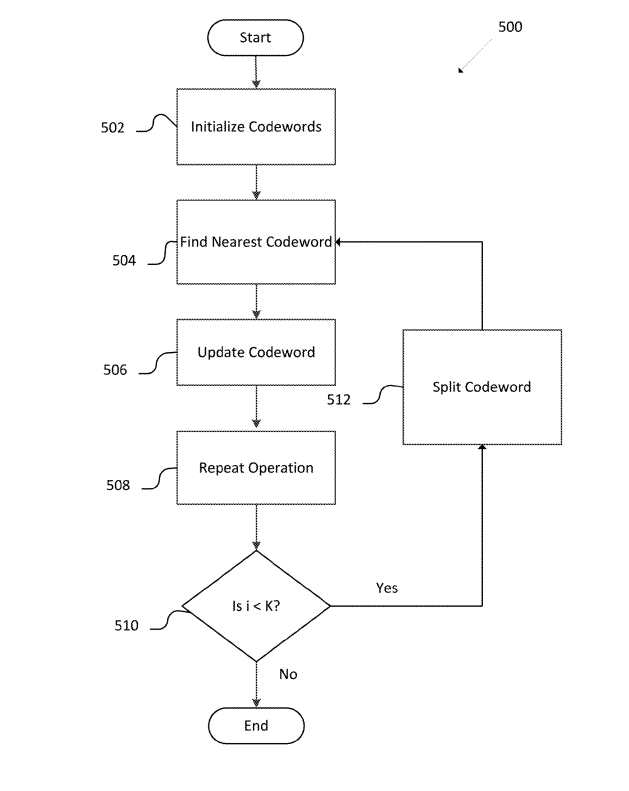
Questo brevetto arriva giusto dopo l’annuncio di Microsoft di aver riunito i team di Microsoft Research e Cortana sotto lo stesso tetto.
Cosa ne pensate? Fatecelo sapere nei commenti.








.){kind=link}